

Das Dienstprogramm wget lädt Webseiten, Dateien und Bilder über die Linux-Befehlszeile aus dem Web herunter. Sie können einen einzelnen wget-Befehl zum Herunterladen von einer Site verwenden oder eine Eingabedatei zum Herunterladen mehrerer Dateien über mehrere Sites einrichten. Laut Handbuchseite kann wget auch dann verwendet werden, wenn sich der Benutzer vom System abgemeldet hat. Verwenden Sie dazu den Befehl nohup.
Funktionen des Befehls wget
Sie können ganze Websites mit wget herunterladen, und konvertieren Sie die Links so, dass sie auf lokale Quellen verweisen, sodass Sie eine Website offline anzeigen können. Das Dienstprogramm wget wiederholt auch einen Download, wenn die Verbindung unterbrochen wird, und wird an der Stelle fortgesetzt, an der sie aufgehört hat, wenn dies möglich ist, wenn die Verbindung wiederhergestellt wird.
Weitere Funktionen von wget sind:
- Laden Sie Dateien mit HTTP, HTTPS und FTP herunter.
- Downloads fortsetzen.
- Konvertieren Sie absolute Links in heruntergeladenen Webseiten in relative URLs, damit Websites offline angezeigt werden können.
- Unterstützt HTTP-Proxys und Cookies.
- Unterstützt dauerhafte HTTP-Verbindungen.
- Kann im Hintergrund ausgeführt werden, auch wenn Sie nicht angemeldet sind.
- Funktioniert unter Linux und Windows.
So laden Sie eine Website mit wget herunter
In diesem Handbuch erfahren Sie, wie Sie diesen Linux-Blog herunterladen:
wget www.ever
Bevor Sie beginnen, erstellen Sie mit dem Befehl mkdir einen Ordner auf Ihrem Computer und wechseln Sie dann mit dem Befehl cd in den Ordner.
Beispielsweise:
mkdir dailylinuxuser
cd dailylinuxuser
wget www.ever
Das Ergebnis ist eine einzelne index.html-Datei, die den von Google abgerufenen Inhalt enthält. Die Bilder und Stylesheets werden bei Google gespeichert.
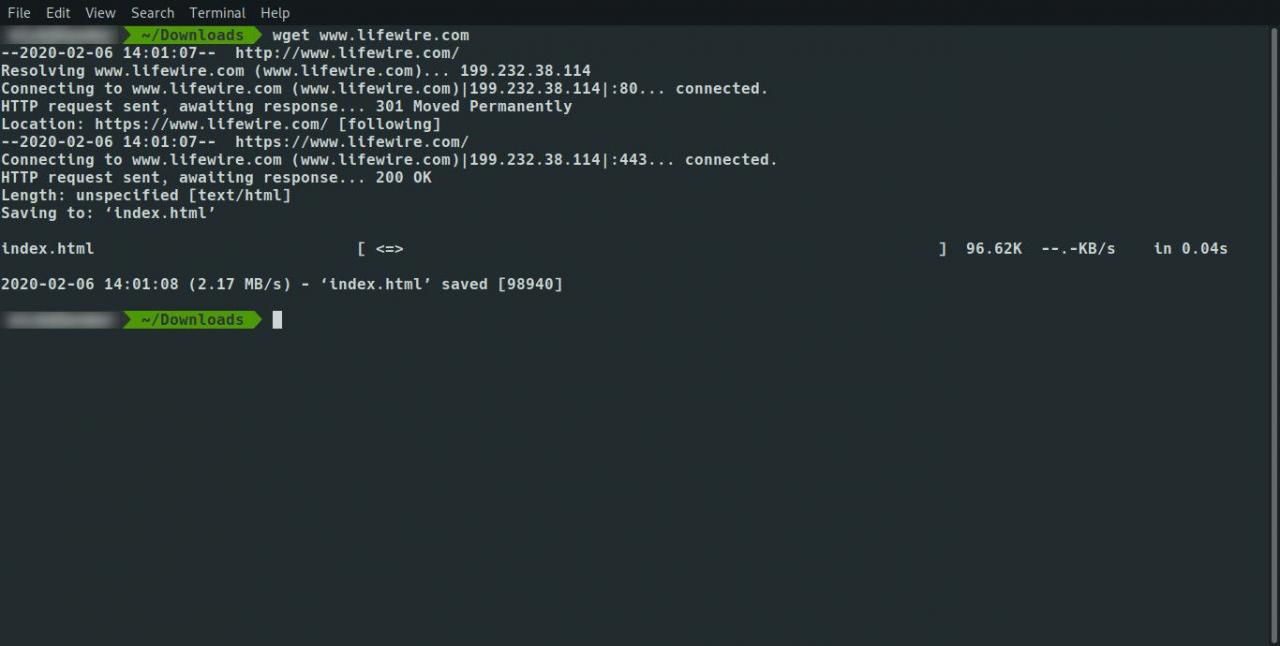
Verwenden Sie den folgenden Befehl, um die vollständige Site und alle Seiten herunterzuladen:
wget -r www.ever
Dadurch werden die Seiten rekursiv bis zu maximal 5 Ebenen tief heruntergeladen. Fünf Ebenen tief reichen möglicherweise nicht aus, um alles von der Site zu bekommen. Verwenden Sie die -l Wechseln Sie wie folgt, um die Anzahl der Ebenen festzulegen, zu denen Sie wechseln möchten:
wget -r -l10 www.ever
Wenn Sie eine unendliche Rekursion wünschen, verwenden Sie Folgendes:
wget -r -l inf www.ever
Sie können auch die ersetzen inf mit 0, was das gleiche bedeutet.
Es gibt noch ein Problem. Möglicherweise erhalten Sie alle Seiten lokal, aber die Links auf den Seiten verweisen auf den ursprünglichen Ort. Es ist nicht möglich, lokal zwischen den Links auf den Seiten zu klicken.
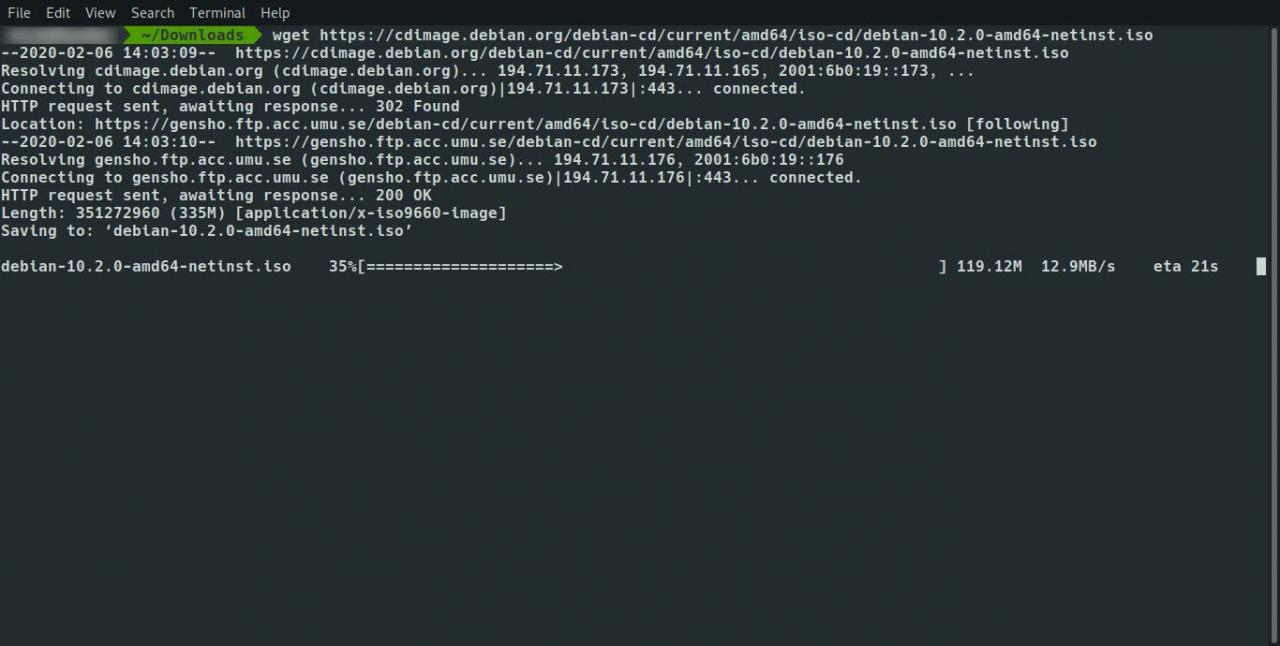
Um dieses Problem zu umgehen, verwenden Sie die -k Wechseln Sie wie folgt, um die Links auf den Seiten so zu konvertieren, dass sie auf das lokal heruntergeladene Äquivalent verweisen:
wget -r -k www.ever
Wenn Sie einen vollständigen Spiegel einer Website erhalten möchten, verwenden Sie den folgenden Schalter, wodurch die Notwendigkeit der Verwendung der Website entfällt -r, -k, und -l Schalter.
wget -m www.ever
Wenn Sie eine Website haben, können Sie mit diesem einfachen Befehl eine vollständige Sicherung erstellen.
Führen Sie wget als Hintergrundbefehl aus
Sie können wget als Hintergrundbefehl ausführen lassen, sodass Sie Ihre Arbeit im Terminalfenster fortsetzen können, während die Dateien heruntergeladen werden. Verwenden Sie den folgenden Befehl:
wget -b www.ever
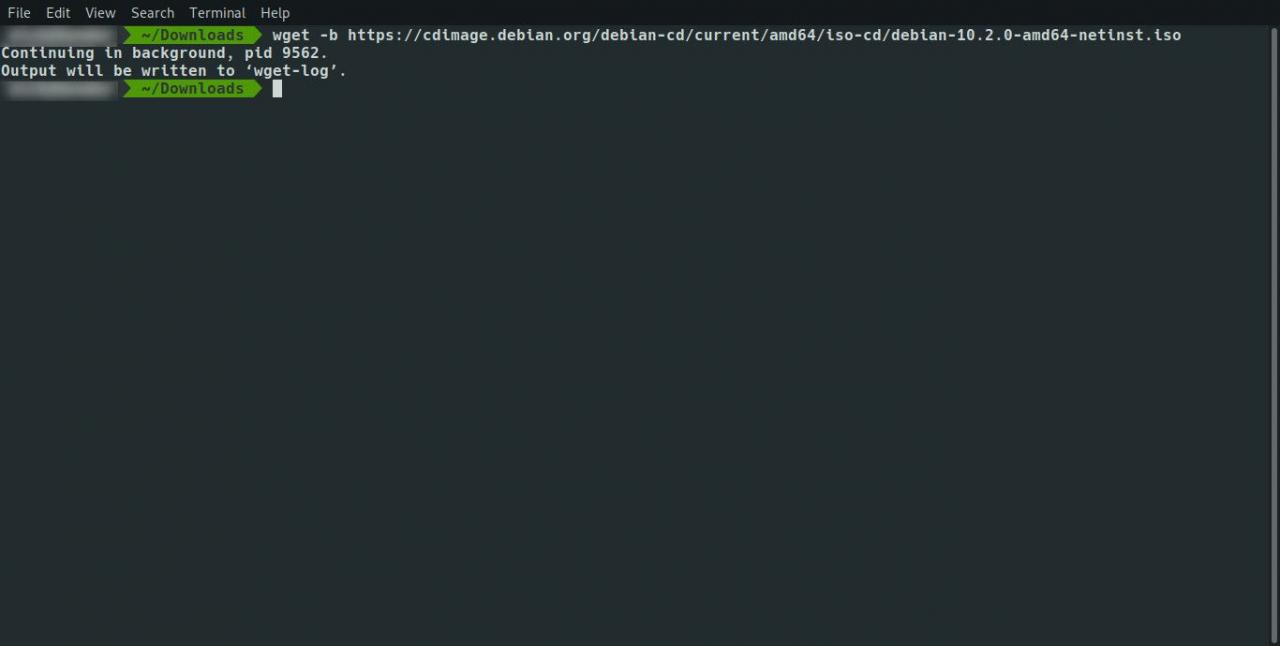
Sie können Schalter kombinieren. Verwenden Sie den folgenden Befehl, um den Befehl wget im Hintergrund auszuführen und gleichzeitig die Site zu spiegeln:
wget -b -m www.ever
Sie können dies wie folgt weiter vereinfachen:
wget -bm www.ever
Protokollierung
Wenn Sie den Befehl wget im Hintergrund ausführen, werden keine der normalen Nachrichten angezeigt, die an den Bildschirm gesendet werden. Verwenden Sie den Befehl tail, um diese Nachrichten an eine Protokolldatei zu senden, damit Sie den Fortschritt jederzeit überprüfen können.
Verwenden Sie den folgenden Befehl, um Informationen aus dem Befehl wget in eine Protokolldatei auszugeben:
wget -o / path / to / mylogfile www.ever
Das Gegenteil ist, dass überhaupt keine Protokollierung und keine Ausgabe auf dem Bildschirm erforderlich ist. Verwenden Sie den folgenden Befehl, um alle Ausgaben wegzulassen:
wget -q www.ever
Von mehreren Websites herunterladen
Sie können eine Eingabedatei zum Herunterladen von vielen verschiedenen Websites einrichten. Öffnen Sie eine Datei mit Ihrem bevorzugten Editor oder dem Befehl cat und listen Sie in jeder Zeile der Datei die Websites oder Links auf, von denen heruntergeladen werden soll. Speichern Sie die Datei und führen Sie den folgenden Befehl wget aus:
wget -i /
Abgesehen davon, dass Sie Ihre Website sichern oder etwas zum Herunterladen zum Offline-Lesen finden, ist es unwahrscheinlich, dass Sie eine gesamte Website herunterladen möchten. Es ist wahrscheinlicher, dass Sie eine einzelne URL mit Bildern herunterladen oder Dateien wie Zip-Dateien, ISO-Dateien oder Bilddateien herunterladen.
In diesem Sinne müssen Sie Folgendes nicht in die Eingabedatei eingeben, da dies zeitaufwändig ist:
- http://www.myfileserver.com/file1.zip
- http://www.myfileserver.com/file2.zip
- http://www.myfileserver.com/file3.zip
Wenn Sie wissen, dass die Basis-URL identisch ist, geben Sie in der Eingabedatei Folgendes an:
- file1.zip
- file2.zip
- file3.zip
Sie können dann die Basis-URL als Teil des Befehls wget wie folgt angeben:
wget -B http://www.myfileserver.com -i /
Wiederholungsoptionen
Wenn Sie eine Warteschlange mit Dateien zum Herunterladen in einer Eingabedatei einrichten und Ihren Computer zum Herunterladen der Dateien laufen lassen, kann die Eingabedatei während Ihrer Abwesenheit hängen bleiben und erneut versuchen, den Inhalt herunterzuladen. Sie können die Anzahl der Wiederholungsversuche mit dem folgenden Schalter angeben:
wget -t 10 -i /
Verwenden Sie den obigen Befehl in Verbindung mit dem -T Wechseln Sie wie folgt, um ein Zeitlimit in Sekunden anzugeben:
wget -t 10 -T 10 -i /
Der obige Befehl wird 10 Mal wiederholt und für jeden Link in der Datei 10 Sekunden lang eine Verbindung hergestellt.
Es ist auch unpraktisch, wenn Sie 75% einer 4-Gigabyte-Datei über eine langsame Breitbandverbindung herunterladen, nur damit die Verbindung unterbrochen wird. Verwenden Sie den folgenden Befehl, um mit wget erneut zu versuchen, von wo aus der Download beendet wurde:
wget -c www.myfileser
Wenn Sie einen Server hämmern, mag der Host ihn möglicherweise nicht und blockiert oder beendet Ihre Anforderungen. Sie können eine Wartezeit angeben, um festzulegen, wie lange zwischen den einzelnen Abrufen gewartet werden soll:
wget -w 60 -i /
Der obige Befehl wartet zwischen jedem Download 60 Sekunden. Dies ist nützlich, wenn Sie viele Dateien aus einer Hand herunterladen.
Einige Webhosts erkennen möglicherweise die Frequenz und blockieren Sie. Sie können die Wartezeit wie folgt zufällig festlegen, damit es so aussieht, als würden Sie kein Programm verwenden:
wget --random-wait -i /
Download-Limits schützen
Viele Internetdienstanbieter wenden Download-Beschränkungen für die Breitbandnutzung an, insbesondere für diejenigen, die außerhalb einer Stadt leben. Möglicherweise möchten Sie ein Kontingent hinzufügen, damit Sie Ihr Download-Limit nicht überschreiten. Sie können dies folgendermaßen tun:
wget -q 100m -i /
Die -q Befehl funktioniert nicht mit einer einzelnen Datei. Wenn Sie eine Datei mit einer Größe von 2 Gigabyte herunterladen, verwenden Sie -q 1000m verhindert nicht das Herunterladen der Datei.
Das Kontingent wird nur angewendet, wenn rekursiv von einer Site heruntergeladen wird oder wenn eine Eingabedatei verwendet wird.
Durch Sicherheit kommen
Bei einigen Websites müssen Sie sich anmelden, um auf die Inhalte zugreifen zu können, die Sie herunterladen möchten. Verwenden Sie die folgenden Schalter, um den Benutzernamen und das Passwort anzugeben.
wget --user = yourusername --password
Auf einem Mehrbenutzersystem, wenn jemand das ausführt ps Befehl können sie Ihren Benutzernamen und Ihr Passwort sehen.
Andere Download-Optionen
Standardmäßig ist die -r switch lädt den Inhalt rekursiv herunter und erstellt dabei Verzeichnisse. Verwenden Sie den folgenden Schalter, um alle Dateien in einen einzelnen Ordner herunterzuladen:
Das Gegenteil davon ist, die Erstellung von Verzeichnissen zu erzwingen, die mit dem folgenden Befehl erreicht werden können:
So laden Sie bestimmte Dateitypen herunter
Wenn Sie rekursiv von einer Site herunterladen möchten, aber nur einen bestimmten Dateityp wie MP3 oder ein Bild wie PNG herunterladen möchten, verwenden Sie die folgende Syntax:
wget -A &
Das Gegenteil davon ist, bestimmte Dateien zu ignorieren. Vielleicht möchten Sie keine ausführbaren Dateien herunterladen. Verwenden Sie in diesem Fall die folgende Syntax:
wget -R &
Cliget
Es gibt ein Firefox-Add-On namens Cliget. So fügen Sie dies zu Firefox hinzu:
-
Besuchen Sie https://addons.mozilla.org/en-US/firefox/addon/cliget/ und klicken Sie auf zu Firefox hinzufügen .
-
Klicken Sie auf die installieren Klicken Sie auf die Schaltfläche, wenn sie angezeigt wird, und starten Sie Firefox neu.
-
Um Cliget zu verwenden, besuchen Sie eine Seite oder Datei, die Sie herunterladen möchten, und klicken Sie mit der rechten Maustaste. Ein Kontextmenü mit dem Namen cliget wird angezeigt, und es gibt Optionen dafür Kopieren nach wget und Kopie zum Einrollen.
-
Klicken Sie auf die kopiere nach wget Option, öffnen Sie ein Terminalfenster, klicken Sie mit der rechten Maustaste und wählen Sie Einfügen. Der entsprechende Befehl wget wird in das Fenster eingefügt.
Dies erspart Ihnen die Eingabe des Befehls.
Zusammenfassung
Der Befehl wget verfügt über eine Reihe von Optionen und Schaltern. Geben Sie Folgendes in ein Terminalfenster ein, um die Handbuchseite für wget zu lesen:
Mann wget
#goog-gt-tt {display:none !important;}.goog-te-banner-frame {display:none !important;}.goog-te-menu-value:hover {text-decoration:none !important;}body {top:0 !important;}#gtranslate_element {display:none!important;}
var gt_not_translated_list = ["wget www.ever","wget -r www.ever","wget -r -l10 www.ever","wget -r -l inf www.ever","wget -r -k www.ever","wget -m www.ever","wget -b www.ever","wget -b -m www.ever","wget -bm www.ever","wget -q www.ever","wget -i /","file1.zip","file2.zip","file3.zip","wget -B http://www.myfileserver.com -i /","wget -t 10 -i /","wget -t 10 -T 10 -i /","wget -c www.myfileser","wget -w 60 -i /","wget --random-wait -i /","wget -q 100m -i /","Cliget"];
document.cookie = "googtrans=/auto/de; domain=.balogs.xyz";
document.cookie = "googtrans=/auto/de";
function GTranslateElementInit() {new google.translate.TranslateElement({pageLanguage: 'auto',layout: google.translate.TranslateElement.InlineLayout.SIMPLE,autoDisplay: false,multilanguagePage: true}, 'gtranslate_element');}
Hallo Suzanne,
wenn ich mein wget zum download eines festen Verzeichnisses aufrufe, klappt alles bis zum Login. Aber dann kommt Meldung:
Logging in as XXXX … Logged in!
==> SYST … done. ==> PWD … done.
==> TYPE I … done. ==> CWD (1) /buchhaltung …
No such directory ‚buchhaltung‘.
Er findet das Verzeichnis /buchhaltung nicht, aber es ist da.
Was kann da schief laufen?
Beste Grüsse Gerd